编译了一个d8程序用于验证和利用漏洞,相关附件下载
CheckBound优化流程
首先在原有的simplified-lowering阶段,CheckBound节点并不被消除,而是设置为kAbortOnOutOfBounds模式,并替换为CheckedUint32Bounds。
1 | void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) { |
而在此之前,该位置如下,可见原先利用节点消除的漏洞利用方法不能使用了。
1 | if (lower()) { |
在Effect linearization阶段,CheckedUint32Bounds节点会被优化成Uint32LessThan,并绑定上其True和False分支。
1 | Node* EffectControlLinearizer::LowerCheckedUint32Bounds(Node* node, |
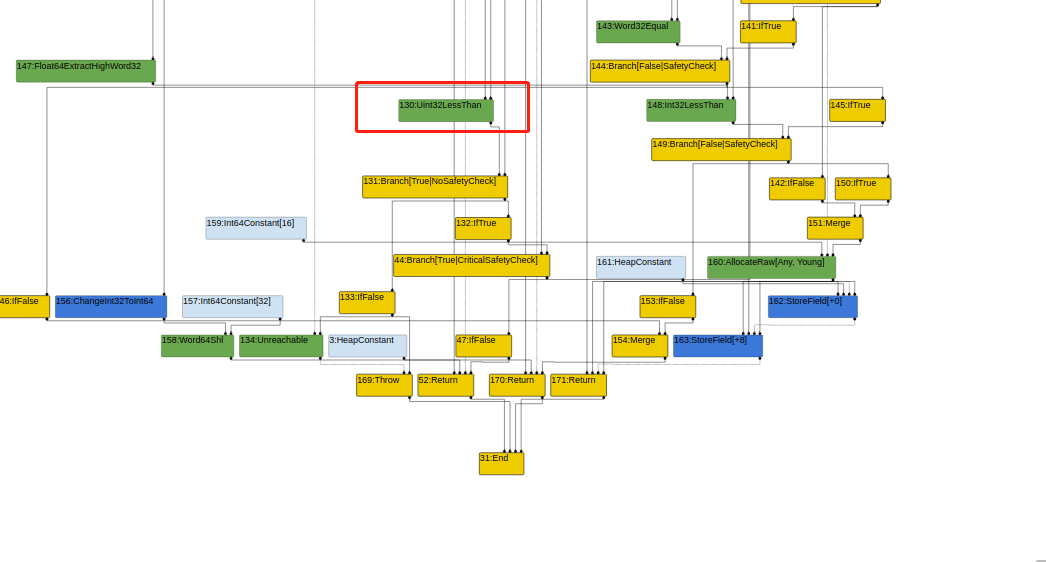
而在lateoptimize阶段,将其优化为左值<右值这个表达式,即一个永真或者永假条件。
1 | // Perform constant folding and strength reduction on machine operators. |
此后,另一个分支就变成了一个不可达的分支,最终在brancheliminate中被剪掉,达到和早期未patch版本同样的目的,但要求多了很多。
题目分析
而从题目来看,题目只patch了两个字符,就是在上面
1 | return ReplaceBool(m.left().Value() < m.right().Value()); |
改为了
1 | return ReplaceBool(m.left().Value() < m.right().Value() + 1); |
这样的话,就算达到访问一个element的下一个节点,这个checkBound也会被优化掉,从而有个off-by-one,如果能达到这一点,就和*ctf 2019的oob这题一模一样了,但那题的实现是增加了一个builtin函数,不需要利用优化,而此题需要在优化的前提下才能用,而且必须使CheckBound达到上述代码的位置。
测试样例分析
测试代码:
1 | var opt_me2 = () => { |
可以发现使用上述测试样例并不能触发OOB,其原因也十分有趣,同样来源于优化过程。
首先通过--trace-turbo对优化过程的IR进行记录,发现在LoopPeeling阶段,44节点是一个值比较结点,而47结点是从element中读取数据,也就是实际执行arr[index]的这个节点。
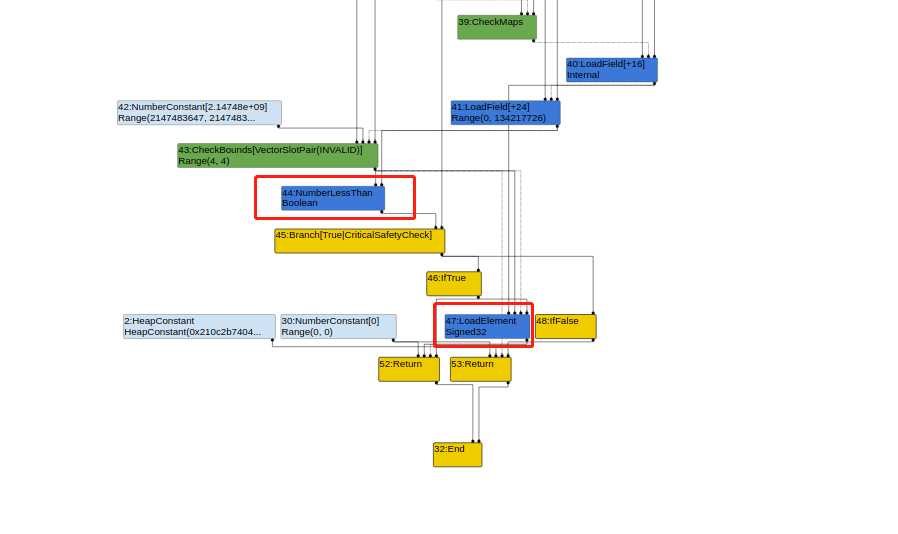
但在下一阶段loadelimination中,比较44和47两个节点都消失了,最终结果将返回2结点(undefined)。
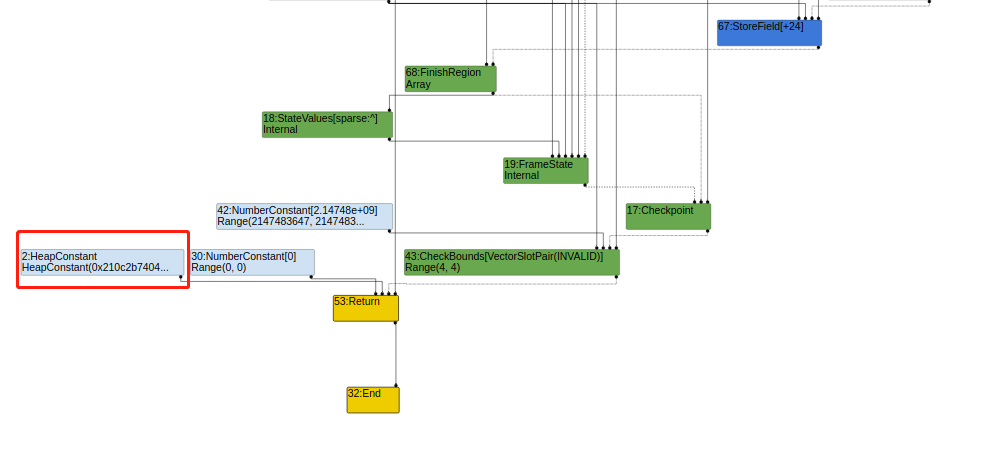
可以查看一下loadelimination都做了什么,从源码中可以看到主要以AddReducer方法添加了10个reducer
1 | void Run(PipelineData* data, Zone* temp_zone) { |
而在graph_reducer.ReduceGraph中将分别对每个节点调用上述添加的10个*::Reduce()方法。
1 | Reduction GraphReducer::Reduce(Node* const node) { |
使用trace-turbo-reduction对节点的修改和替换细节进行分析,可以发现在如下部分,首先是NumberLessThan(43, 16)内容被TypeNarrowingReducer更新,然后被ConstantFoldingReducer替换成HeapConstant固定值false,最终导致45节点True的分支变成不可达的节点,最终被DeadCodeElimination清理掉,造成没有触发OOB
1 | - In-place update of 44: NumberLessThan(43, 16) by reducer TypeNarrowingReducer |
首先跟踪TypeNarrowingReducer,可以看到当opcode是kNumberLessThan时,如果左节点的最小值大于右节点的最大值时,类型会被op_typer_.singleton_false();,是一个HeapConstant
1 | Reduction TypeNarrowingReducer::Reduce(Node* node) { |
从日志中可以发现其左节点是43,从IR可以发现其范围是[4,4],右节点是16 ,是一个常量值[4]
1 | - Replacement of 41: LoadField[tagged base, 24, Range(0, 134217726), kRepTaggedSigned|kTypeInt32, NoWriteBarrier, mutable](68, 17, 12) with 16: NumberConstant[4] by reducer LoadElimination |
因此,在ConstantFoldingReducer::Reduce中,44节点将被生成的一个HeapConstant节点替代。
1 | Reduction ConstantFoldingReducer::Reduce(Node* node) { |
因此,想要触发OOB必须规避掉以上路径。可以从43节点和16节点两方面考虑。首先说16节点,其来自于41节点的优化
1 | - In-place update of 41: LoadField[tagged base, 24, Range(0, 134217726), kRepTaggedSigned|kTypeInt32, NoWriteBarrier, mutable](68, 17, 12) by reducer RedundancyElimination |
当op搜索的参数field_index不是0时,到相应的object中找到相关偏移的节点代替掉这个LoadField节点,可见这个就是直接取出了要访问element的长度,似乎无法改变。
1 |
|
而另一节点43 typer的路径如下:
1 | Reduction Reduce(Node* node) override { |
SIMPLIFIED_OTHER_OP_LIST定义如下
1 |
|
因此这个分支就变成了
1 | case IrOpcode::kCheckBounds: \ |
TypeCheckBounds定义如下,取第一个和第二个输入节点的类型,调用CheckBounds
1 | Type Typer::Visitor::TypeCheckBounds(Node* node) { |
CheckBounds定义如下,显然index是一个实际的范围,而length负责控制其最大边界,而最终取index与mask的交集。
1 | Type OperationTyper::CheckBounds(Type index, Type length) { |
1 |
|
对于测试demo,其0、1两个节点的范围如下:
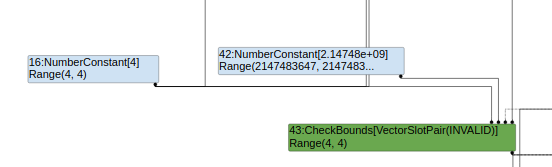
显然就是取[4,4]和[0,2147483646]的交集,因此CheckBounds的typer结果是[4,4]。最终导致满足uintlessthan的优化条件left_type.Min() >= right_type.Max(),被优化成永假。
poc构造
综上,分析了测试样例不能触发OOB的原因,首先要想办法绕过loadelimination阶段对loadelement节点的消除。
可以发现一个显然的途径是在CheckBounds的typer阶段做文章,如果让CheckBounds节点的范围并非单一值而是一个范围,保证最小值小于要访问element的范围,就不会满足消除的条件(left_type.Min() >= right_type.Max()),而核心问题是对第一个输入的节点范围的扩展,因为CheckBounds的范围基本由此确定。
长亭发表的一篇writeup中提到了两种解决方案,第一种是对index增加一个and操作idx &= 0xfff;,这种方法会在原来NumberConstant[4]下面增加一个SpeculativeNumberBitwiseAnd节点。
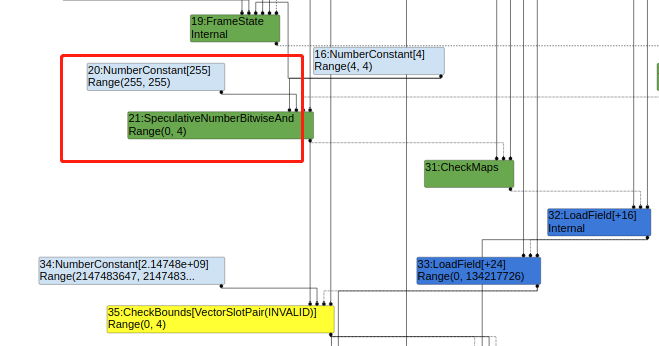
而这个节点的typer实现如下:
1 | Type OperationTyper::NumberBitwiseAnd(Type lhs, Type rhs) { |
其中lmin、lmax为255,rmin、rmax为4,因此最终该节点的范围(0,4),传递至CheckBounds节点并不满足这消除条件,可以触发漏洞。
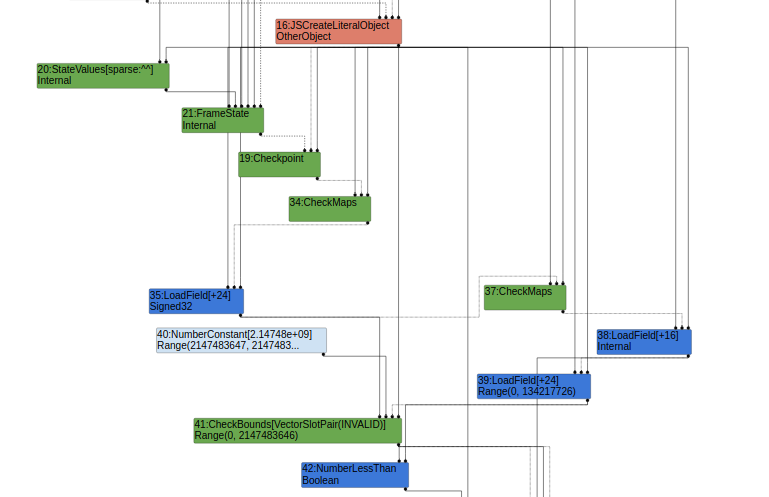
第二种,由于逃逸分析阶段在LoadElimination后一阶段,因此在typer时,无法直接分析出从array中取出的index具体值,只能将其分析为Signed32,最终CheckBounds的范围为(0,2147483646)
此外,还可以利用Phi节点来达到同样的目的,当某个值存在分支时,Turbofan会将增加一个phi节点,并将这两个值都加入节点的范围去传递,那么poc同样可以这样构造
1 | var opt_me = (x) => { |
则构造的IR图如下
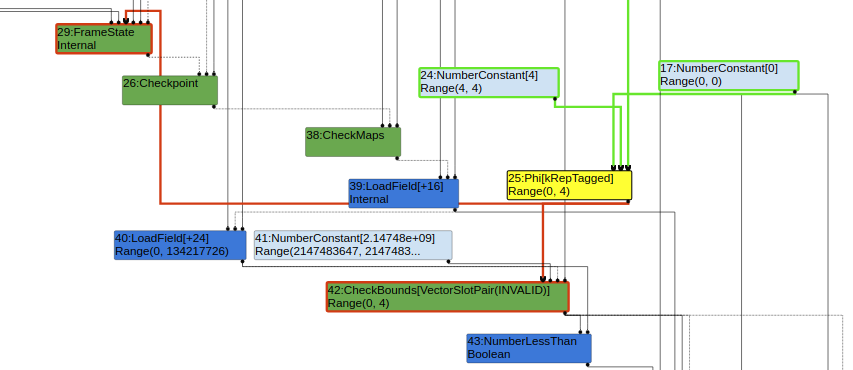
执行结果如下:
1 | # p4nda @ ubuntu in ~/chromium/v8/v8/out.gn/x64.debug/log on git:749f0727a2 x [10:39:33] C:130 |
addrof原语构造
现在在element上存在一个off-by-one。对于一个JSArray,其数据结构本身与element内存分布存在两种布局,一种是elememt在低地址,一般用var a = [1.1,1.2,1.3]这样的方式构建;另一种是element在高地址,一般用var a = Array(4)这样的方式构建。由于二者内存位置紧邻,因此,可以通过off-by-one泄露或者修改一个对象的map地址,从而造成type confuse。
一个简单的想法就是将一个存放了obj的JSArray的map改为全部存放double类型的JSArray map。
首先泄露比较简单,利用之前的poc可以将arr的map,并将arr加入一个全局的Array防止map被释放。
1 | function get_map_opt(x){ |
在拿到了一个PACKED_DOUBLE_ELEMENTS类型的map时,就可以对一个PACKED_ELEMENTS类型的JSArray造类型混淆了。这里有一个坑点,就是不能对一个PACKED_ELEMENTS类型的map位置直接写一个double,因为element一共有三种类型,并且是不可逆的改变,向PACKED_ELEMENTS类型的element写double会将double转换为一个HeapNumber,也是一个HeapObject,而非double值本身。
例如:
1 | # p4nda @ ubuntu in ~/chromium/v8/v8/out.gn/x64.debug on git:749f0727a2 x [10:26:24] |
因此需要做一下转换,对一个写满double_map的JSArray(PACKED_DOUBLE_ELEMEMTS类型)造类型混淆,使其混淆为PACKED_ELEMENT类型,这样再去其中的一个变量向PACKED_ELEMENT类型的JSArray写入,即可将其混淆为PACKED_DOUBLE_ELEMENT类型,从而读出其中object的地址。
1 | function prepare_double_map_opt(x){ |
任意地址读写构造
JSArray数据可以存放于三个位置,以数字下标访问的存放于elements,以value:key访问的如果是初始化的时定义的,直接存于数据结构中,其余后续加入的存于properties,而对于键值对访问的数据,其键值查找方式存于map中,那么如果可以对一个JSArray的map进行修改,通过键值对访问的方式,对后续数据进行修改。
首先,获取一个含有properties很多的一个JSArray的map,
1 | function get_array_map_opt(x){ |
通过布局使一个JSArrayBuffer恰好处于紧邻一个JSArray的高地址位置,这样将JSArray的map修改为以上map,就可以不断修改backing_store了,由于这个布局相对稳定,因此可以重复使用。
1 | function get_victim_obj_opt(x){ |
通过访问victim_jsarray.a5实际上读写的是victim_arraybuffer的backing_store成员,通过对victim_arraybuffer读写达到任意地址读写的目的。
最终,通过wasm对象,找到rwx-区域,执行shellcode。
EXP
1 | function gc() |
由于chromium编译太慢了,用d8代替结果: